На главную страницу
Графический план выполнения запросов SQL Server в действии
Tim Chapman (оригинал: See SQL Server graphical execution plans in action)
Перевод Моисеенко С.И.
Планы выполнения - один из лучших инструментов для
настройки ваших запросов на SQL Server. В этой статье я остановлюсь на нескольких
основных моментах в графическом плане выполнении, чтобы помочь Вам лучше понять,
как SQL Server использует индексы. Я также предлагаю идеи относительно того, как
сделать ваши запросы быстрее.
Установка моего примера
Я должен создать таблицу, которую буду использовать повсюду в примерах, и загрузить
в нее некоторые данные. Я загружу довольно большое количество данных в таблицу для
того, чтобы SQL Server не только сканировал таблицу при извлечении данных. Обычно,
если таблица относительно мала, SQL Server будет сканировать ее вместо того, чтобы
решить использовать наилучшую комбинацию индексов, поскольку в этом случае сканирование
таблицы займет меньше времени.
CREATE TABLE [dbo].[SalesHistory]
(
[SaleID] [int] IDENTITY(1,1),
[Product] [varchar](10) NULL,
[SaleDate] [datetime] NULL,
[SalePrice] [money] NULL
)
GO
SET NOCOUNT ON
DECLARE @i INT
SET @i = 1
WHILE (@i <=50000)
BEGIN
INSERT INTO [SalesHistory](Product, SaleDate, SalePrice)
VALUES ('Computer', DATEADD(ww, @i, '3/11/1919'),
DATEPART(ms, GETDATE()) + (@i + 57))
INSERT INTO [SalesHistory](Product, SaleDate, SalePrice)
VALUES('BigScreen', DATEADD(ww, @i, '3/11/1927'),
DATEPART(ms, GETDATE()) + (@i + 13))
INSERT INTO [SalesHistory](Product, SaleDate, SalePrice)
VALUES('PoolTable', DATEADD(ww, @i, '3/11/1908'),
DATEPART(ms, GETDATE()) + (@i + 29))
SET @i = @i + 1
END
Следующий оператор создает кластерный индекс на столбце SaleID для таблицы SalesHistory.
Это в некотором роде произвольный выбор для кластерного индекса в таблице, но для
данного примера он имеет смысл, так как SaleID будет увеличиваться при добавлении
новых строк. Создание этого индекса физически упорядочит данные в таблице в порядке
возрастания значений SaleID.
CREATE CLUSTERED INDEX idx_SalesHistory_SaleID
ON SalesHistory(SaleID ASC)
Выполните этот оператор, чтобы включить статистику ввода/вывода для наших запросов.
SET STATISTICS IO ON
Чтобы вывести план выполнения для запросов, которые я буду демонстрировать, необходимо
включить соответствующую опцию. Для этого я щелкну правой кнопкой мыши в окне редактора
запросов (Query Editor) и выберу команду меню Include Actual Execution Plan. См.
рисунок A.
Рисунок А
Следующий оператор выбирает строку из таблицы SalesHistory на основании значения
в столбце SaleID, на котором имеется кластерный индекс.
SELECT * FROM SalesHistory WHERE SaleID = 9900
Вы можете видеть графический план выполнения и статистику для этого запроса на рисунке
B.
Рисунок В
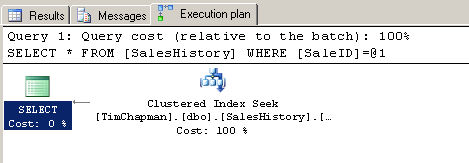
Оптимизатор выполнил поиск по кластерному индексу (Clustered Index Seek), который
является технически самым быстрым типом поиска в таблице, которые Вы увидите. Обратите
внимание, что было выполнено три логических операции чтения для поиска этой строки
в таблице:
Table 'SalesHistory'. Scan count 1, logical reads 3, physical reads 0, read-ahead
reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Нижеприведенный скрипт ищет все записи в таблице SalesHistory, для которых продуктом
является PoolTable. В настоящее время нет никакого индекса на этом столбце, при
этом имеется только три различных значения в этом столбце для всех строк таблицы.
Возможными значениями могут быть только PoolTable, Computer или BigScreen.
SELECT * FROM SalesHistory WHERE Product = 'PoolTable'
План выполнения вышеприведенного запроса показывает, что было выполнено сканирование
кластерного индекса (Clustered Index Scan), поскольку для таблицы имеется кластерный
индекс. Напомню, что кластерный индекс сортирует таблицу в порядке, заданном ключами
индекса. В данном случае кластерный индекс реально не помогает мне, потому что все
таки необходимо выполнить сканирование, чтобы найти все случаи, когда продукт равен
PoolTable. См. рисунок C.
Рисунок С
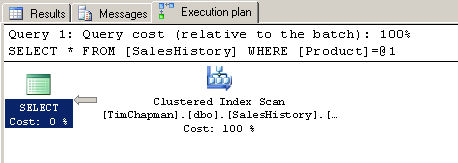
Table 'SalesHistory'. Scan count 1, logical reads 815, physical reads 0, read-ahead
reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Итак, что случится, если мы создадим индекс на столбце Product в таблице SalesHistory?
Если Вы выполните следующий оператор создания некластерного индекса для этой таблицы,
то заметите, что ничего не изменилось, даже с индексом на столбце Product. План
выполнения и число логических операций чтения то же самое из-за селективности значений
в столбце. Имеется только три различных значения для всех строк в этой таблице,
поэтому дополнительный индекс не сможет помочь в нашем случае, поскольку требуется
вытащить слишком много записей. Индексы наиболее выгодны, когда они строятся на
столбцах, которые содержат много различных значений.
CREATE NONCLUSTERED INDEX idx_SalesHistory_Product ON SalesHistory(Product ASC)
Я удаляю индекс, так как он никак не изменит результатов остальных моих примеров.
DROP INDEX SalesHistory.idx_SalesHistory_Product
SaleDate в таблице SalesHistory преднамеренно уникален, что видно из скрипта, который
я использовал для генерации данных. Если я создам индекс на SaleDate и буду искать
конкретные данные, следует ожидать, что мой поиск будет использовать этот индекс
намного более эффективно, чем мои индексы на столбце Product.
CREATE NONCLUSTERED INDEX idx_SalesHistory_SaleDate ON SalesHistory(SaleDate ASC)
SELECT SaleDate, Product FROM SalesHistory WHERE SaleDate = '1971-05-11 00:00:00.000'
План выполнения ниже подтверждает мое ожидание. Из-за более высокой селективности
столбца SaleDate использовался поиск по индексу (index seek). Этот план выполнения
также демонстрирует то, что известно как Поиск Закладки (Bookmark Lookup). Bookmark
Lookup имеет место, когда SQL Server нашел запись в некластерном индексе, которая
удовлетворяет поисковому запросу, но требуемые столбцы в списке столбцов предложения
SELECT, не включены в индекс, таким образом SQL Server должен обратиться к диску
и найти дополнительные данные. В этом плане выполнения Index Seek находит строку,
а поиск в кластерном индексе (Clustered Index Seek) есть поиск закладки (Bookmark
Lookup). В SQL Server 2000 для этого используется описание Bookmark Lookup, а в
SQL Server 2005 SP2 - Key Lookup (поиск ключа).
Обычно следует по возможности избегать поиска закладок из-за дополнительных операций
чтения, присутствующих в поиске необходимых данных. Типичное решение проблемы -
это включение дополнительных столбцов, которые Вы читаете, в индекс, используемый
для поиска данных. Это будет работать не в каждом случае, поэтому нужно приложить
некоторые усилия, чтобы найти сбалансированное решение. См. рисунок D.
Рисунок D
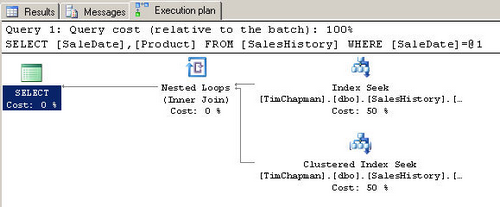
Table 'SalesHistory'. Scan count 1, logical reads 5, physical reads 0, read-ahead
reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Теперь я хочу видеть план выполнения для того же самого запроса, но без кластерного
индекса на столбце SaleID, для этого мне нужно удалить кластерный индекс.
DROP INDEX SalesHistory.idx_SalesHistory_SaleID SELECT SaleDate, Product FROM SalesHistory
WHERE SaleDate = '1971-05-11 00:00:00.000'
В плане выполнения вы можете увидеть, что поиск по кластерному индексу (Clustered
Index Seek) превращается в поиск ID записи (RID Lookup). Это тот же поиск закладки,
но иначе названный, поскольку таблица не имеет кластерного индекса. Здесь есть один
очень интересный момент, связанный с числом выполненных логических операций чтения.
Данный запрос выполняет только четыре операции логического чтения, в то время как
предыдущий запрос с кластерным индексом выполнял пять логических операций чтения.
Лишнее чтение обусловлено тем фактом, что кластерный индекс должен был использоваться
для нахождения строки данных. Всякий раз, когда некластерный индекс получает доступ
на таблице, которая имеет кластерный индекс, последний, в конечном счете, используется,
чтобы найти нужные строки. Поскольку таблица SalesHistory в настоящее время не имеет
кластерного индекса, этот запрос стал на одно логическое чтение быстрее. См. рисунок
E.
Рисунок E
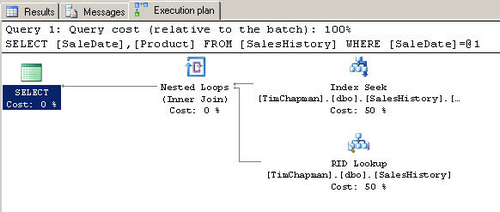
Table 'SalesHistory'. Scan count 1, logical reads 4, physical reads 0, read-ahead
reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Это не означает, что наличие кластерного индекса может замедлять ваши запросы. Каждая
таблица должна иметь кластерный индекс, потому что это сортирует данные и помогает
в поиске по другим индексам. Этот единственный случай запроса, который оказался
немного более быстрым, потому что не было никакого кластерного индекса для таблицы.
Увеличение скорости незначительна в этом случае, и почти любому другому поиску по
таблице будет помогать кластерный индекс.
Поскольку моя таблица сейчас не имеет кластерного индекса, я хочу повторно создать
его. См. следующий код:
CREATE CLUSTERED INDEX idx_SalesHistory_SaleID ON SalesHistory(SaleID ASC)
Table 'SalesHistory'. Scan count 1, logical reads 811, physical reads 0, read-ahead
reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'SalesHistory'. Scan count 1, logical reads 814, physical reads 0, read-ahead
reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
К таблице SalesHistory было два обращения при воссоздании кластерного индекса, потому
что когда кластерный индекс добавляется к таблице, любые некластерные индексы на
той же таблице должны быть перестроены. Некластерный индекс должен сначала получить
доступ к кластерному индексу, прежде чем он сможет возвратить данные. Некластерный
индекс, который у меня был на столбце SaleDate, был перестроен после уже того, как
был построен кластерный индекс. См. рисунок F.
Рисунок F
Настройка ваших запросов
Примеры в этой статье не являются категорическим руководством для построения индексов
или чтения планов выполнения и настройки запросов. Моя цель состоит в том, чтобы
указать Вам правильное направление для изучения настройки ваших собственных запросов.
Настройка запросов - не точная наука, и потребности вашей базы данных будут изменяться
с течением времени. Чем больше Вы экспериментируете с возможными комбинациями индексов,
тем более успешно Вы будете их использовать.
В следующий раз я планирую еще раз обратиться к графическим планам выполнения и
их чтению для запросов, в которых выполняется соединение таблиц.
01-10-2007
На главную страницу